Creating Dimensions from WikiData
Posted · 5 min read · 874 words
Introduction
A common requirement in business intelligence applications is to align the facts to be reported on with standard data dimensions such as country or region.
The question immeadiately arises: ‘where can we source the data to build the dimension?’, followed shortly after by: ‘… and how can we keep it current?’.
This post demonstrates how to create a database dimension of cities using Open Data from wikidata.org and Microsoft Azure Mapping Data Flows.
What’s WikiData?
If you’re unfamilar, WikiData is a repository of structured data created from public contributions. Some data is input directly, other data is extracted from sources like the info boxes on Wikipedia.
Data is available to download as in the RDF format under an open data license.
Our goal is to use the city data of WikiData to create a dimension of cities within countries.
Each city on WikiData has a unique URI about which different statements are made. For example, here’s
Understanding the source data
Data within WikiData is available for download in RDF. To meet our goal, we want to extract every entity from WikiData that meets the following criteria:
- Is of type city (instance of Q515)
- Is contained within a country (has a property of P17)
- Has an English langage label
WikiData makes this data available through a number of different mechanisms.
In theory a SPARQL query would work to extract this data, however, the Query Service quickly timed out.
Another option would be to use Linked Data Fragments to download the slices of WikiData matching these criteria. Unfortunately, the LDF service only returns 100 results per invocation, so a lot of client side orchestration would be required.
In the end, the simplest solution was to download all ’truthy’ statements in a single 25Gb Bzip2 file and process that.
Processing large datasets in Azure
Azure has a number of big data tools that can be used to manipulate a large data set such WikiData. For this job, Mapping Data Flows fit the bill. Under the covers, these are Spark pipelines that are orchestrated from Azure Data Factory on Azure hosted integration runtimes.
Like most Big Data tools, Spark prefers data that is line based. For RDF that means using the ntriples format which explicity makes each triple a separate line. For example, the following three statements:
<http://www.wikidata.org/entity/Q172> <http://schema.org/name> "Toronto"@en .
<http://www.wikidata.org/entity/Q172> <http://www.wikidata.org/prop/direct/P31> <http://www.wikidata.org/entity/Q515> .
<http://www.wikidata.org/entity/Q172> <http://www.wikidata.org/prop/direct/P17> <http://www.wikidata.org/entity/Q16> .
Say: Entity Q712 is called ‘Toronto’ in English, is a City (Q515) and is in Canada (Q16)
To build a table of cities, all the pipeline has to do is find and process all the lines in the data set that match the criteria above.
Step by step
Downloading the data
The first step is to download the database dump to blob storage. This is a single pipeline using the Copy Data step, from an HTTP source
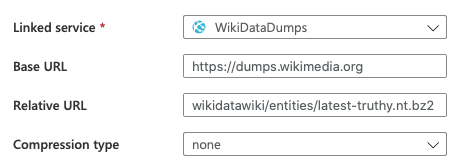
to blob storage:

Note that everything is binary at this stage.
Configuring a source and sink dataset for Spark
Next, create a new dataset that declares the compression and the closest we can explain ntriples to Azure:
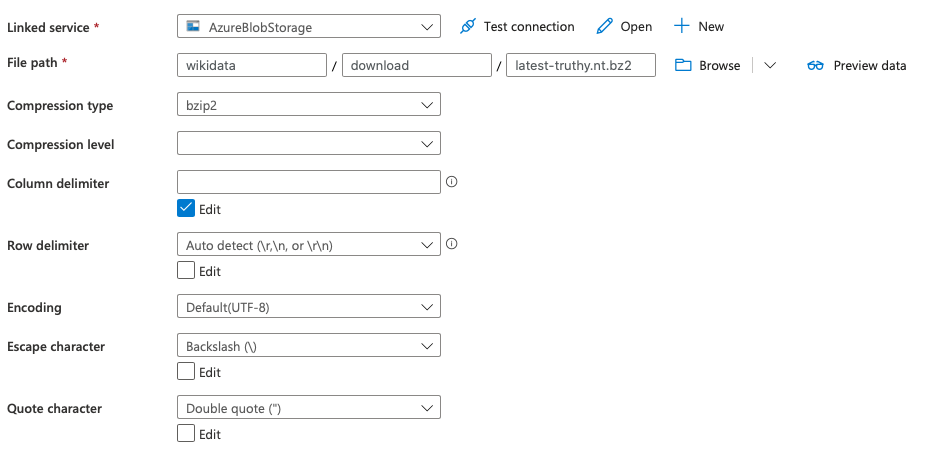
Finally add a SQL database staging table with the columns (cityName, etc.) being mapped to. Declare these all as nvarchar(MAX) to keep things simple.
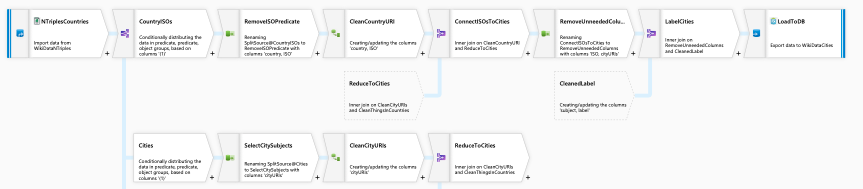
The dataflow
Finally, configure a dataflow to process the dump from WikiData.
The first step is to split the incoming stream using the split operator to string match to either subject, predicate or object on each ntriple line into separate candidate streams:
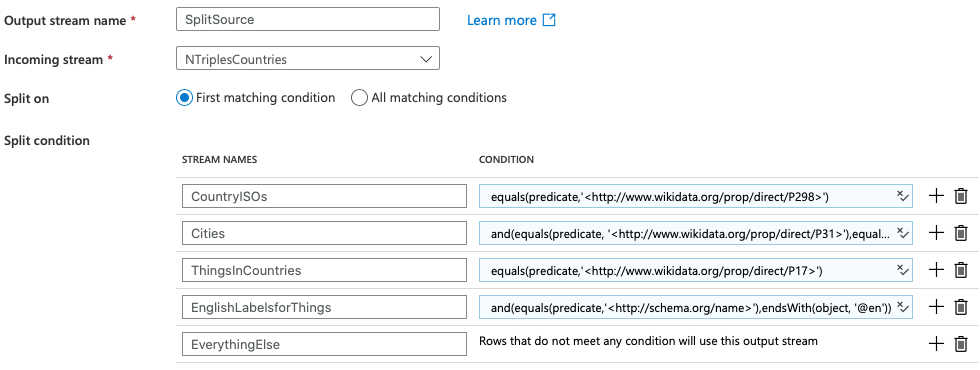
From there the steps are fairly repetitive:
- remove unneeded columns, rename remaining columns from generic to specific ‘subject’ to ‘cityURI’
- remove < and > delimiters
- inner join each stream on the matches of subjects and objects
Finally, the resulting ~7,500 rows are loaded to a staging table in the data warehouse along with the ISO three digit country code used to join the cities to an existing country dimension. This process is orchestrated by invoking the data flow from a data factory pipeline.
One last thing - dealing with Unicode
The ntriples format uses Java style \u0024 Unicode escape sequences. Mapping Data Flows don’t have an easy way to map these to Unicode. The solution is this elegant hack in the merge stored procedure on the SQL side: string concatenate the city name into a JSON blob and then use json_value to extract it:
select json_value('{"n":"'+cityName+'"}',$.n)
from stg.wikiDataCities
Performance & Conclusion
Without any work on optimizing partitioning, this job takes ~45 minutes on a 32 core general purpose compute cluster.
When creating data dimensions it can be tempting to just download the data and hand wrangle into the database. The challenge with this approach is that the data inevitably changes over time. This can lead to much head scratching in the team as everyone tries to remember how the data was loaded last time.
Using WikiData as a source gives us an evergreen set of data that can be refreshed on demand. Further, if a needed city is missing, it can be added to WikiData enriching the content from everyone. The challenge of WikiData is that RDF serialization is poorly supported by regular ETL tools. However, the ntriples format is close enough to permit us to use tools such as Mapping Data Flows.