Adding Wikipedia links to WikiData extracts
Posted · 2 min read · 351 words
Back in August I posted a technique to create database dimensions from WikiData using Azure Data Factory to extract from the dump files in ntriples format.
We recently had a requirement to add the Wikipedia links for each entity in the dimension - both for use as a primary key (since the Wikipedia URI is unique and human friendly) as well as for quality control.
That should be pretty easy: much of the WikiData entities have links to the matching object on Wikipedia. For example, if you extracting cities, look at the RDF for Rosemount you’ll see the relationships for eack Wikipedia entry in different languages:
<https://en.wikipedia.org/wiki/Rosemount,_Minnesota> a schema:Article ;
schema:about wd:Q1986505 ;
schema:inLanguage "en" ;
schema:isPartOf <https://en.wikipedia.org/> ;
schema:name "Rosemount, Minnesota"@en .
Or, in NTriples:
<https://en.wikipedia.org/wiki/Rosemount,_Minnesota> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://schema.org/Article> .
<https://en.wikipedia.org/wiki/Rosemount,_Minnesota> <http://schema.org/about> <http://www.wikidata.org/entity/Q1986505> .
<https://en.wikipedia.org/wiki/Rosemount,_Minnesota> <http://schema.org/inLanguage> "en" .
<https://en.wikipedia.org/wiki/Rosemount,_Minnesota> <http://schema.org/isPartOf> <https://en.wikipedia.org/> .
<https://en.wikipedia.org/wiki/Rosemount,_Minnesota> <http://schema.org/name> "Rosemount, Minnesota"@en .
<https://en.wikipedia.org/> <http://wikiba.se/ontology#wikiGroup> "wikipedia" .
So, I thought, should be pretty easy to add to the existing split operation and match on rows with the predicate of <http://schema.org/about> and then join on the URI of the desired object. To ensure we only get the relationship to the English version of Wikipedia, either
- ‘cheat’ and do a startsWith
<https://en.comparison on the subject or, - a second split matching for predicate of
<https://schema.org/inLanguage>with object"en"followed by an inner join on the subject to restrict the about relationships.
I opted for the second option as semantically more correct, added the relevant splits and joins and ran the pipeline. Nothing came out. Huh? It took a full scan of the file to realize the the truthy file doesn’t contain the schema.org predicates (for a more detailed discussion of the difference, see WikiData).
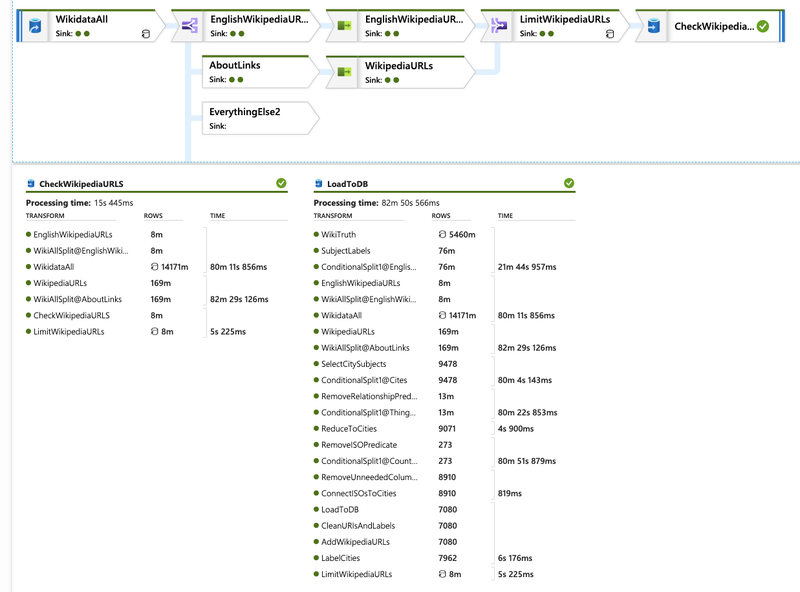
To get those, one must turn to the full dump, a 122GB bzip2 file. Once downloaded, I amended my data flow to accept two source files, the truthy pipeline stayed as is, the Wikipedia relationships I extracted from the all file.
Adding this functionality pushed run time from ~50 minutes to ~80 (see image above). Not bad for a five fold increase in input data.